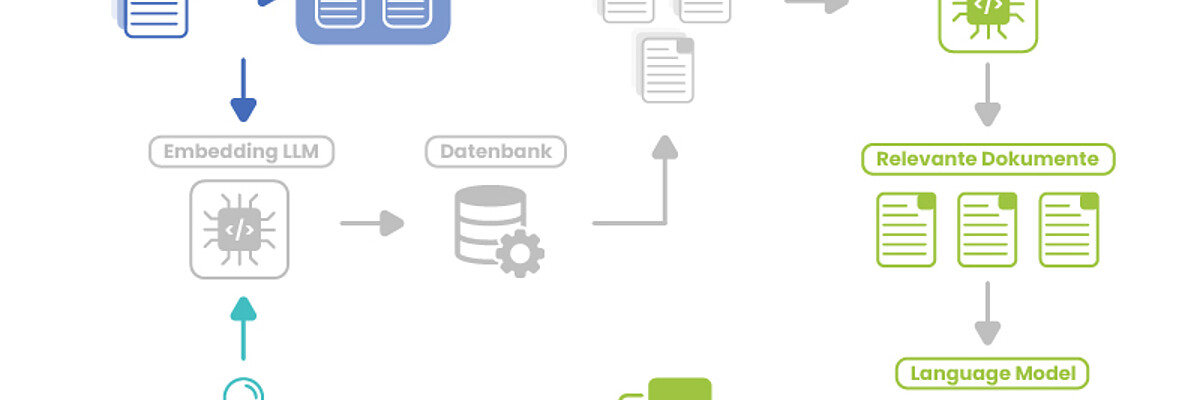
The retriever (the "R" in RAG) searches for contextually appropriate content in the vector database at lightning speed. This often leads to many potentially relevant documents being found, but also those with little actual relevance.
These irrelevant documents in the context window increase the risk of noise-in-context-problem. This reduces the precision of the final answer, as the LLM has to process unnecessary information - which costs time, tokens and quality.
The solution: a reranker.
Reranking (also known as cross-encoding) reduces the documents found by the retriever to the truly relevant content.
To do this, each document returned by the retriever is checked for its relevance to the question posed:
A relevance score is assigned to each pair of candidates (query and chunk).
Only the X documents with the highest score are kept, the rest are discarded.
The technical advantage of the cross encoder:
In contrast to the fast but coarse-grained retriever, the reranker can capture the subtle interactions between query and chunk. As a result, it determines the actual relevance much more precisely and sorts the documents accordingly.
This optimizes the use of the limited context window and makes the LLM responses more robust against irrelevant information.
Practical tip: Options for rerankers
Open-weight models:
Models such as ms-marco-MultiBERT-L-12 can be self-hosted and often even run without GPU on CPU. Important: Choose a multilingual model if required.Specialized APIs:
providers such as Cohere, Jina or voyageai provide highly optimized commercial reranking models via APIs.
Both variants can be easily integrated into existing workflows and frameworks such as LangChain or Neuron-AI.
Our conclusion: The biggest advantage lies in the significantly better responses of the LLMs (the accuracy can be improved by 20-35%, see link). The fact that additional tokens and time are saved during processing by the LLM is a welcome bonus.